Abstract
본 논문에서는 인간의 키포인트 추정에 기반한 수화 번역 시스템을 제안한다.
컴퓨터 비전 분야의 많은 문제들은 깊은 신경망 모델을 훈련시키기 위해 엄청난 양의 데이터 세트를 필요로 한다는 것은 잘 알려져 있으며, 수화 번역 문제에 있어서는 고품질의 교육데이터를 수집하기가 훨씬 어려워서 상황이 더욱 악화된다.
본 논문에서는 고해상도 및 품질의 11,578개의 동영상으로 구성된 KETIsign 언어 데이터 세트를 소개한다.
-> 각 나라마다 수화의 차이가 있다는 점을 감안할 때, KETIsign 언어 데이터셋은 한국어 수화 번역에 대한 후속 연구를 위한 출발점이 될 수 있다.
KETI 수화 데이터셋을 이용 -> 얼굴, 손, 신체 부위에서 추출한 인간의 키포인트를 활용하여 수화 영상을 자연어 문장으로 번역하기 위한 신경망 모델을 개발한다.
이때, 획득된 인간 키포인트 벡터는 키포인트의 평균과 표준 편차에 의해 정규화되고 Sequence-to-Sequence 구조에 기초한 번역 모델에 대한 입력으로 사용된다.
1. Introduction
수화 인식 또는 번역은 독립적인 문법을 구어체 언어로 해석하는 연구
-> 시각언어는 손의 다양한 정보와 이 문법에 따른 얼굴 표정을 결합하여 정확한 의미를 제시하며, 이 문제는 컴퓨터 비전에서 도전적인 주제이며 청각 장애인에게 중요한 주제

Convolutional Neural Networks (CNNs)는 이미지 분류, 객체 검출, 의미 분할, 동작 인식과 같은 다양한 시각 작업에서 우수한 성능을 기록한 강력한 모델
독특한 문법을 가진 Sign Language => 손의 모양과 움직임을 통해 언어적 의미를 표현 + 감정과 특정 의도를 제시하는 얼굴 표현을 통해 표현 + 또한 많은 수화는 손과 얼굴 표정의 연속적인 포즈를 포함하는 구어체 소화 순서의 다른 단어와 문장을 나타내며, '손 언어'는 각 문자를 한 손 모양으로 알파벳으로만 나타내는데, 이는 수화로 단 하나의 인간 의도를 묘사하는 것조차 그 사례의 수가 엄청나게 많다는 것을 암시.
본 논문은 한국의 professional signer 11명으로부터 수집된 한국어 수화 데이터 세트를 구축한다. 데이터셋은 419단어에 해당하는 한국어 수화를 기록한 고해상도 영상과 각종 비상상황과 관련된 105문장으로 구성됐다. 그리고 손, 자세, 얼굴의 인간 키포인트를 기반으로 수화 번역 시스템을 제시
2. KETI Sign Language Dataset
KETI 데이터 셋은 청각장애인의 다양한 비상사태에 처했을 때의 한국어 수화를 이해하기 위해 구축 => 따라서 응급상황의 비교적 일반적인 대화 내용을 면밀히 검토하고, 그러한 상황에서 사용되는 유용한 105개의 문장과 419개의 단어를 선택
<KETI Dataset>
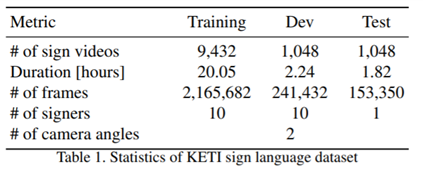
- KETI 수화 데이터 세트는 초당 30프레임, 앞면과 두 개의 카메라 각도로 기록된 11,578개의 풀하이 정의(HD) 비디오로 구성.
- 각 서명자는 데이터 세트에 대해 총 1,048개의 비디오를 기록.
- 훈련 및 검증 세트를 위해 11명의 서명자 중에서 10명의 서명자를 선택하고 훈련 세트의 각 기호에 대해 9개의 서명 비디오를 선택. 나머지 서명 비디오는 유효성 검사 세트에 할당. 훈련 세트 또는 유효성 검사 세트에 서명 비디오가 없는 단일 서명자의 테스트 세트 구성자.
- 또한 위에서 언급한 긴급 상황에서 유용한 문장에 해당하는 105개의 기호 각각에 대해 한국어로 5개의 다른 자연어 문장으로 주석을 달았으며, 모든 사인 비디오에 해당 sequences of gloosses로 주석을 달았는데, 여기서 gloss는 단위 기호에 해당하고 수화를 번역하는 데 사용되는 고유한 단어. (예를 들어 ‘나는 탄다’는 뜻의 기호는 다음과 같이 ('FIRE', 'SCAR') 순서로 주석을 달 수 있다. 마찬가지로 ‘집에 불이 났다’는 문장도 (‘HOUSE’, 'FIRE')에 의해 표기. )
3. Approach
본 논문에서는 기존의 OpenPose와 같은 라이브러리를 통해 추정된 휴먼키포인트를 기반으로 한 기호인식 시스템을 제안 => 실시간 다인칭 키포인트 탐지를 위한 오픈 소스 툴킷인 OpenPose를 기반으로 시스템을 개발. (OpenPose는 18개의 키포인트가 신체 포즈에서 나온 총 130개의 키포인트, 213개의 키포인트가 각 손에서 나온, 70개의 키포인트를 정면에서 추정할 수 있으며, 수화 인식을 위한 특징 추출기로 OpenPose를 선택한 주된 이유는 다양한 유형의 변형이 강건하기 때문)
3-1. Human Keypoint Detection by OpenPose
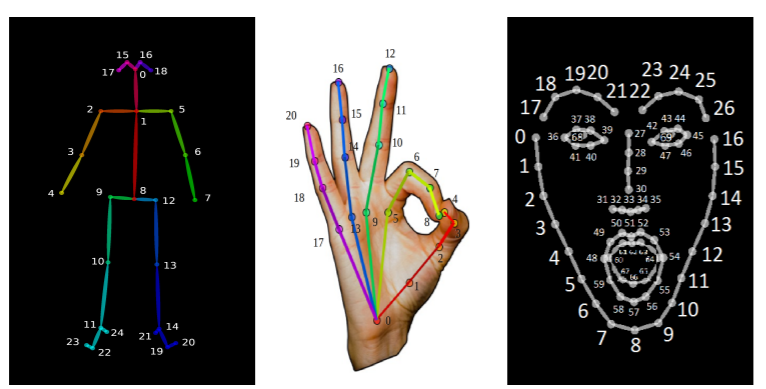
- 본 논문의 Recognition system은 인체만을 감지하기 때문에 서로 다른 어수선한 배경에서 견고함
- 추출된 키포인트의 분산은 무시할 수 있으므로, 인간의 키포인트 탐지에 기반한 시스템은 signer에 관계없이 잘 작동한다. 또한, 벡터 표준화 기법을 적용하여 signer에 의존하는 분산을 더욱 감소시킨다.
- 본 시스템은 다기능성으로 인해 향후 큰 잠재력을 가진 키포인트 탐지 시스템의 개선의 이점을 누릴 수 있음. 예를 들어, 인간 키포인트 탐지 시스템은 관련 데이터 세트가 확보된 다른 인간의 행동과 행동을 인식하는데 사용될 수 있다
- 마지막으로, 데이터 세트의 규모가 충분히 크지 않을 때 높은 수준의 피쳐를 사용해야 함 => 수화 데이터셋의 경우, 많은 professional signers가 고품질의 수화 비디오를 기록하는데 활용되어야 하기 때문에 다른 데이터셋보다 수집하기가 더 어려움
3-2. Feature Vector Normalizaion
작은 데이터 세트로 수화 번역을 진행하는데 주요 어려움 중 하나는 signer에 따라 동일한 수화가 매우 다르게 보이기 때문에 발생하는 큰 시각적 분산이다.
인체의 키포인트를 추정하여 얻은 특징벡터를 활용하더라도 프레임 내 키포인트의 절대위치나 신체부위의 스케일은 매우 다를 수 있기 때문에, 목적에 잘 맞는 객체 2D 정규화 (object 2D normalization) 라는 특수 정규화 방법을 적용.고수준의 인간 키포인트를 추출한 후, 데이터의 분산을 줄이기 위해 벡터의 평균 및 표준 편차를 사용하여 특징 벡터를 정규화함.
2D 특징 벡터를

특징백터는 n개의 요소로 구성되는데, 각 요소는 아래와 같으며 인간 부분의 단일 키포인트를 나타냄.
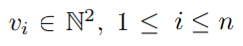
아래는 각 요소는

각각 비디오 프레임을 통해 키포인트 vi의 x-와 y-좌표가 각각 vix, viy 두 개의 정수로 구성된다.
주어진 특징 벡터 V에서 우리는 다음과 같이 두 특징 벡터를 추출할 수 있다.
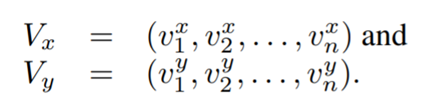
간단히 말해서, 순서를 유지하면서 키포인트의 x와 y 좌표를 별도로 수집한다.
그런 다음 x 좌표 벡터 Vx를 다음과 같이 정규화한다.

여기서 Vx(bar)는 Vx의 평균이고 (Vx)는 Vx의 표준 편차다.
(Vy* 또한 유사하게 계산되었음)
마지막으로, 두 개의 정규화된 벡터를 연결하여 아래와 같이 최종 특징 벡터를 형성

이는 신경망의 입력 벡터로 사용된다 !
본 논문에서 하체 부분의 키포인트가 수화 인식에 필요하지 않다고 가정하고, 따라서 OpenPose에서 검출한 137개의 키포인트에서 124개의 키포인트만 사용.

왜냐하면 6개의 키포인트는 그림 2에서 볼 수 있듯이 양쪽 발, 무릎, 골반과 같은 하체 부위에 해당하기 때문. 각 기호 비디오에서 10개에서 50개의 키프레임을 무작위로 샘플로 추출한다.따라서 입력 특징 벡터의 dimension은 248 x |V|이며, 여기서 |V| ∈ {20, 30, 40, 50}
3-3. Frame Skip Sampling for Data Augmentation
소 데이터 세트로 신경망을 훈련하는 데 가장 큰 어려움은 훈련된 모델이 유효성 검사 및 테스트 세트의 데이터로 잘 일반화되지 않는다는 것이다. 데이터 세트의 크기가 본 논문의 문제에서 일반적인 경우보다 훨씬 작기 때문에, 훈련 데이터를 증강하기 위해 비디오 분류와 같은 비디오 데이터를 처리하는 데 일반적으로 사용되는 랜덤 프레임 스킵 샘플링을 사용한다.
여기서 비디오의 여러 대표적 특징을 무작위로 추출한다.
f1에서 fl까지의 l 프레임을 포함하는 sign video S = (f1, f2, ...,fl)가 주어졌을 때, 우리는 n개의 고정된 프레임의 수를 무작위로 선택한다. 그런 다음, 먼저 프레임 사이의 평균 간격 길이를 다음과 같이 계산한다.
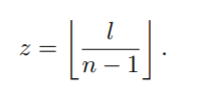
먼저 다음의 Y = (y, y + Z, y + 2z, ..., y+(n-1)z) ∈ N ^n 시퀀스로부터 인덱스를 갖는 프레임들의 시퀀스를 추출한다.
(여기서 y = [ (l-z(n-1))/2] 이며 그것을 baseline sequence라고 부름)
그런 다음, 무작위 정수 시퀀스R = (r1, r2, . ., rn)∈ [1, z]^ n 를 생성하고 기준 시퀀스와 랜덤 시퀀스의 합을 계산한다.
마지막 인덱스의 값은 [1, l]의 값으로 잘리며, 우리는 기호의 'key'모멘트를 포함하지 않을 수 있는 프레임의 무작위 시퀀스를 생성하지 않기 위해 길이 l의 임의 시퀀스를 선택하는 대신 baseline sequence에서 시작한다.
3-4. Attention-based Encoder-Decoder Network
LSTMs 또는 GRUs와 같은 RNN 아키텍처를 기반으로하는 encoder-decoder 프레임 워크는 통계적 기계 번역 방법을 성공적으로 대체하면서 신경 기계 번역에 대한 인기를 얻고 있다.
입력 문장 x = (x1, x2, .. , x(Tx))이 주어졌을 때, 인코더 RNN은 다음과 같은 역할을 한다.

여기서 ht ∈ Rn은 시간 t에서 hidden state(지금까지의 입력데이터를 요약한 정보)
전체 입력 문장을 처리한 후 인코더는 다음과 같이 시퀀스를 나타내는 고정 크기 컨텍스트 벡터(fixed-size context vector)를 생성한다.
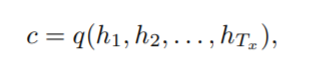
예를 들어, RNN은 LSTM 셀이며 q는 마지막 hidden state인 hTx를 반환한다. 이제 y = (y1, y2, . . . , yTy)는 훈련 세트에서 입력 문장 x에 해당하는 출력 문장이다.
그런 다음 디코더 RNN은 이전에 예측된 모든 단어와 인코더 RNN의 컨텍스트 벡터에 대해 조건화된 다음 단어를 예측하도록 훈련된다. 즉, 디코더는 다음과 같이 조인트 확률을 순서 조건 확률로 분해하여 translation y의 확률을 계산한다.
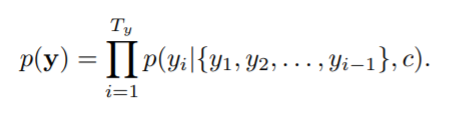
이제 RNN 디코더는 각 조건부 확률을 다음과 같이 계산한다.
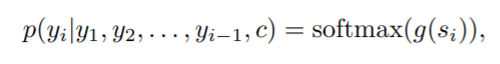
여기서 si는 시간 i 및 g에서 디코더 RNN의 hidden state이며 어휘 크기의 벡터를 출력하는 선형 변환이다.
숨겨진 상태 si는 다음과 같이 계산된다.
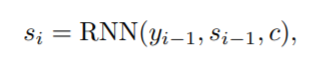
여기서 Yi-1은 이전에 예측된 단어이고,
Si-1은 디코더 RNN의 마지막 숨겨진 상태이며, c는 인코더 RNN에서 계산된 컨텍스트 벡터이다.
컨텍스트 벡터 ci는 인코더에서 숨겨진 상태의 가중치 합으로 계산된다.
Bahdanau attention
Bandanau et al은 고정 길이 컨텍스트 벡터 c가 번역 모델의 성능을 향상시키는 데 병목 현상이라고 추측하고 인코더의 hidden state 에서 관련 부분을 자동으로 검색하여 컨텍스트 벡터를 계산할 것을 제안했고, 실제로 이러한 ‘attention’ 메커니즘은 기계 번역에 국한되지는 않지만 다양한 작업에 실제로 유용함을 입증했다.그들은 다음과 같이 동적으로 계산된 컨텍스트 벡터 ci에 따라 시간 i에서 각 조건부 확률을 정의하는 새로운 모델을 제안했다.

여기서, Si는

에 의해 계산된 시간 i에서 디코더 RNN의 숨겨진 상태이다.
컨텍스트 벡터 ci는 인코더로부터 숨겨진 상태의 가중 합으로 계산된다.
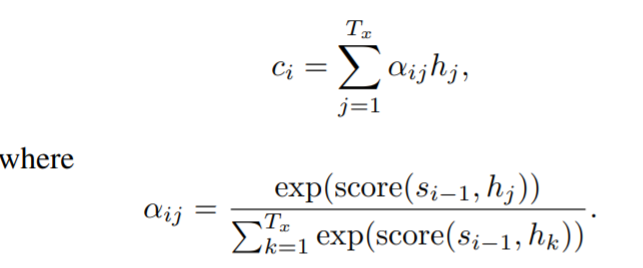
여기서 함수 ‘score’는 인코더와 디코더의 숨겨진 두 상태가 각각 얼마나 잘 일치하는지 계산하는 정렬 함수라고 한다.
예를 들어, si가 시간 i에서 인코더의 숨겨진 상태이고 hj가 시간 j에서 디코더의 숨겨진 상태인 점수(si, hj)는 위치 i를 중심으로 입력 문장의 부분과 위치 j를 중심으로 출력 문장의 부분을 정렬할 확률을 암시한다
Luong attention
나중에 Luong et al은 Bahdananu et al의 attention 메커니즘과 매우 유사한 새로운 attention 메커니즘을 조사 => 하지만 세부 사항에서는 다르다
첫째, 양방향 인코더의 순방향 및 역방향 은닉 상태와 단방향 논스택 디코더의 은닉 상태를 연결하는 대신 인코더와 디코더 모두에서 상위 RNN 계층의 은닉 상태만 사용한다.
둘째, 현재 시간 단계에서 디코더의 은닉 상태를 계산한 후 어텐션 매트릭스를 계산하여 계산 경로를 단순화한다.
그들은 또한 다음과 같이 은닉 상태 간의 정렬 정도를 계산하기 위해 다음 세 가지 스코어링 함수를 제안했다.
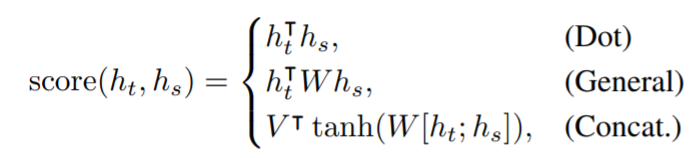
여기서 V와 W는 학습된 가중치
Multi-head attention (Transformer)
이전 인코더-디코더 아키텍처는 RNN 셀을 기반으로 하지만 Vaswani et al. 는 반복 및 회선 없이 attention 메커니즘에만 기반을 둔 완전히 새로운 네트워크 아키텍처를 제안했다. Transformer의 가장 중요한 특징은 다음과 같이 세 가지 방식으로 사용되는 멀티 헤드 어텐션이다.
1. 인코더-디코더 attention: 디코더의 각 위치는 입력 시퀀스의 모든 위치를 처리할 수 있다
2. 인코더 self- attention: 인코더의 각 위치는 인코더의 이전 계층에 있는 모든 위치에 대해 주의를 기울일 수 있다.
3. 디코더 self- attention: 디코더의 각 위치는 디코더에서 그 위치까지의 모든 위치에 주의를 기울인다.
게다가 Transformer는 반복이나 컨볼루션을 사용하지 않기 때문에 모델에는 시퀀스의 순서에 대한 정보가 필요하다.
이 문제를 해결하기 위해 Transformer는 사인 및 코사인 함수를 사용하여 시퀀스에서 단어의 상대 또는 절대 위치에 대한 정보를 포함하는 위치 인코딩을 사용한다.
4. Experimental Results
- 우리는 Python용 오픈 소스 기계 학습 라이브러리인 PyTorch[39]를 사용하여 네트워크를 구현했다.
- Adam 옵티마이저는 초기 학습률이 0.001인 50 Epoch 동안 네트워크 가중치와 편향을 훈련하는 데 사용되었습니다. 또한 확률 0.8의 드롭아웃 정규화와 임계값 5의 그래디언트 클리핑을 사용 => 딥 러닝 훈련에 특화된 다른 데이터 세트에 비해 데이터 세트의 크기와 변동이 작기 때문에 드롭아웃 정규화는 반드시 높아야 한다.
- 바닐라 seq2seq 모델과 두 개의 어텐션 기반 모델을 포함하는 sequence-to-sequence 모델의 경우 숨겨진 상태의 차원은 256이다. Transformer 모델의 경우 256의 입력 및 출력에 대한 차원을 사용.Transformer에 사용된 다른 하이퍼 매개변수는 자체 설정에 예약된 Adam 최적화 프로그램을 포함하여 원래 모델과 동일
- 또한, batch size는 128, Augmentation factor는 100, 선택된 프레임의 수는 50이며, 특별히 지정하지 않는 한 object 2D normalization을 사용. 이러한 언어에서 단순히 공백으로 문장을 단어로 나누면 사전의 크기가 임의로 커질 수 있으므로 주석이 있는 문장을 수행. 이러한 이유로 우리는 한국어의 자연어 처리를 위해 개발된 Python 패키지인 KoNLPy 패키지에서 Kkma 품사(POS) 태거를 사용하여 문장을 POS 수준으로 토큰화했음
- 번역 모델의 성능을 평가하기 위해 기본적으로 올바르게 번역된 단어와 문장의 비율을 의미하는 '정확도'를 계산. 또한 BLEU, ROUGE-L, METEOR, CIDEr 점수와 같이 기계 번역 모델의 성능을 측정하는 데 일반적으로 사용되는 세 가지 유형의 메트릭도 활용
Sentence-level vs Gloss-level training
"IEEE Conference on Computer Vision and Pattern Recognition"에서와 같이 주석 유형에 따른 번역 성능을 비교하는 실험을 수행한다. 각 기호는 고유한 광택 시퀀스에 해당하고 여러 자연어 문장에 해당하므로 광택 수준 번역이 더 나은 성능을 보일 것이라고 쉽게 예측할 수 있다. 실제로, 표 10에 제공된 결과 요약에서 예상을 확인할 수 있다.
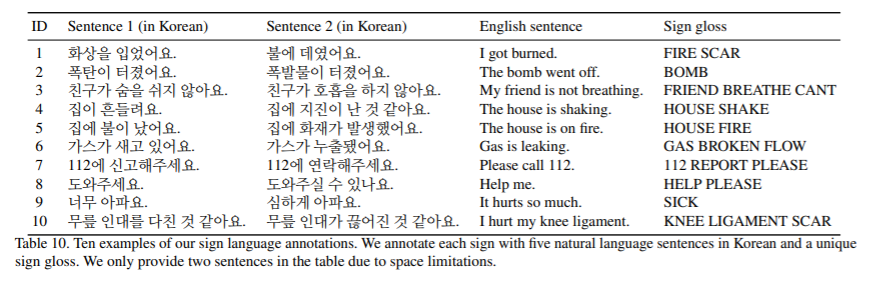
이는 또한 일련의 용어집을 자연어 문장으로 번역하기 위한 향후 작업으로 이어진다. 수화 번역은 수화 비디오에 자연어 문장으로 주석을 추가하는 작업을 두 개의 하위 작업으로 분리하여 수화 번역이 보다 실현 가능한 작업이 될 수 있을 것으로 기대하고 여기서 수화 비디오에 글로 주석을 달고 각 글로스 시퀀스를 자연어 문장으로 주석을 달 수 있다.
Effect of feature normalization methods

특징 정규화 방법이 OpenPose에서 추정한 주요 포인트에 미치는 영향을 평가하기 위해 1) 정규화 없음, 2) 특징 정규화, 3) 객체 정규화, 4) 2차원(2D) 정규화 및 5) 객체 2D 정규화의 5가지 경우를 비교함.
첫 번째 경우 모든 키포인트의 좌표 값을 연결하여 생성된 키포인트 피쳐에 대해 정규화 단계를 수행하지 않습니다. feature normalization에서는 1)과 같이 keypoint feature를 생성하고 전체 feature의 평균과 표준편차로 feature를 normalize한다. 객체 정규화에서는 두 손, 몸, 얼굴에서 얻은 키포인트 특징을 각각 정규화하고 연결하여 프레임을 나타내는 특징을 생성. 또한 x- 및 y 좌표는 별도로. 마지막으로 객체 2D 정규화는 본 논문에서 제안하는 정규화 방법이다.실험 결과를 표 4에 정리하였다.
특히, 정규화 없이 단순히 키 포인트의 x 및 y 좌표를 연결하여 얻은 키 포인트 특징 벡터로 신경망을 훈련할 때 유효성 검사 손실이 감소하지 않는다. 모든 종류의 정규화가 긍정적으로 작동하는 것처럼 보이지만 객체별 정규화와 2D 정규화를 함께 사용할 때 번역 성능이 추가로 향상된다는 사실은 매우 흥미롭다.
Effect of augmentation factor

무작위 프레임 건너뛰기 샘플링에 의한 데이터 증가 효과를 조사하고 실험 결과를 표 5에 요약함.
단일 부호 비디오에서 무작위로 샘플링된 훈련 샘플의 수를 'augmentation factor' 라고 한다.
과적합으로 인해 validation loss가 전혀 감소하지 않기 때문에 random frame sampling으로 데이터를 증가시키지 않은 경우 결과를 포함하지 않는다는 점에 유의해야 한다. 결과는 최적의 Augmentation factor가 실제로 50임을 보여준다. sign 비디오의 평균 프레임 수가 200보다 크고 프레임 간의 평균 간격 길이가 4보다 크다. 그러면 평균적으로 450개의 가능한 임의 시퀀스가 있으므로 결과적으로 정확히 동일한 훈련 샘플을 가질 확률은 정말 낮다. 그러나 결과는 augmentation factor를 증가시키는 것이 어느 시점에서 한계가 있음을 시사한다.
Effect of attention mechanisms

여기에서는 다양한 기계 번역 작업에 특화된 4가지 유형의 인코더-디코더 아키텍처를 비교.
표 2는 Luong et al.의 attention 기반 모델 간의 명확한 대조를 보여줌. Transformer는 독립 서명자의 sign 비디오로 구성된 테스트 세트에 훨씬 더 잘 일반화된다.
Effect of the number of sampled frames
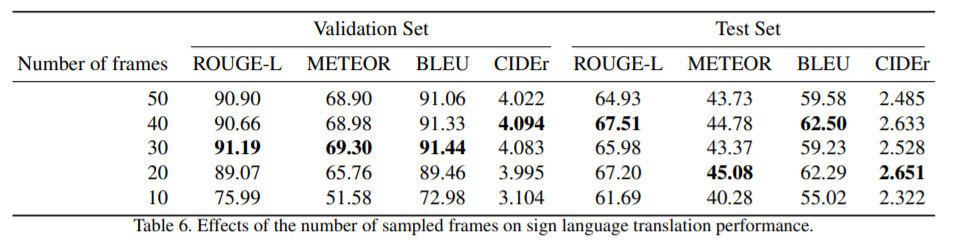
불필요한 프레임을 효율적으로 건너뛰어 추론 엔진의 계산 비용을 줄일 수 있기 때문에 실시간 수화 번역 시스템을 개발할 계획이라면 최적의 프레임 수를 아는 것이 유용하다. 표 6은 샘플링된 프레임의 수가 번역 성능에 영향을 미치는 것을 보여줍니다. sequence to sequence 모델은 모든 가변 길이 입력 시퀀스에 대해 작동하므로 샘플링된 프레임의 수를 반드시 고정할 필요는 없지만, Sequence-to-Sequence 모델의 번역 성능이 소실 그라디언트 문제로 인해 감소하는 경향이 있기 때문에 최적의 프레임 수를 아는 것이 유용하다. 흥미롭게도 실험 결과는 최고의 번역 성능은 검증 세트의 경우 30, 테스트 세트의 경우 50입니다.
Effect of batch size
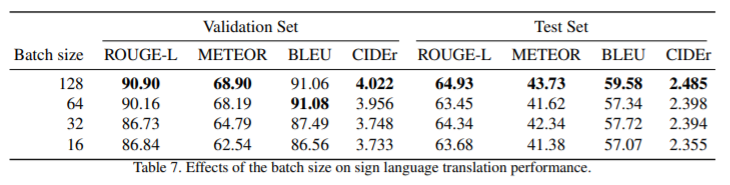
최근에는 작은 배치로 훈련하는 것이 큰 배치로 훈련하는 것보다 테스트 세트에 더 잘 일반화되는 경우가 점점 더 많아지고 있다. 그러나 Table 7에 제시된 실험 결과는 정반대의 현상을 보여주고 있다. 대규모 배치가 어느 정도 과적합을 방지하는 데 유용하다고 알려져 있기 때문에 이는 원본 데이터 세트의 규모 때문이라고 생각
4-1. Ablation study
또한 두 손, 몸, 얼굴에서 키포인트 정보를 사용하는 효과에 대해서도 연구한다.표 8에서 요약한 실험 결과는 손, 얼굴, 신체의 모든 키포인트 정보 중에서 양손의 키포인트 정보가 가장 중요하다는 것을 의미한다.
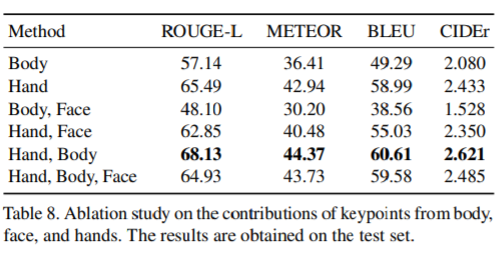
흥미롭게도, 실험 결과는 얼굴에서 나오는 키포인트 정보가 일반적으로 성능을 향상시키는 데 도움이 되지 않는다는 것을 말해준다. 모든 경우에 얼굴 키포인트를 추가하면 성능이 떨어진다.
그 이유가 부분적으로 다른 부분에서 나온 주요 점의 불균형한 수 때문이라고 의심한다. 얼굴에서 키포인트의 수가 70이며 이는 다른 키포인트의 수보다 훨씬 크다. 양손의 핵심 포인트가 분명히 기호를 이해하는 가장 중요한 특징이지만, 신체의 12가지 핵심 포인트가 성과를 높이고 있다는 점에 주목할 필요가 있다. 실제로 각 부품의 좌표를 별도로 정규화하면 서로 부품의 상대적 위치에 대한 정보를 잃게 된다. 예를 들어, 두 손의 상대적인 위치를 양손의 특징 벡터를 정규화하여 추론할 방법이 없다.그러나 손과 대응되는 키포인트도 존재하기 때문에 신체의 키포인트로부터 상대적인 위치를 알 수 있다.
5. Conclusion
본 논문에서는 한국어 구어 문장에 수동으로 주석을 달고 있는 새로운 수화 데이터 세트를 소개하고, Sequence to Sequence 번역 모델을 기반으로 한 신경 수화 번역 모델을 제안하였다. 많은 작업에서 이미 매우 유용한 것으로 입증된 수화 번역 작업에 대한 신경망 기반 알고리즘의 완전한 활용을 크게 저해하는 것은 큰 수화 데이터 세트의 부족으로 잘 알려져 있음
이 때문에 수화영상에서 충분히 낮은 차원의 고차원적 특징을 추출하는 것은 불가피하다고 주장한다. Hidalgo 등에서 개발한 OpenPose라는 오픈 소스 프로젝트에서 추정한 인간 키포인트를 기반으로 새로운 수화 번역 시스템을 성공적으로 훈련할 수 있다. 앞으로 영상의 공간적 특성을 이용한 다양한 데이터 증강 기법을 활용하여 수화 번역 시스템을 개선하는 것을 목표로 한다.
또한 더 많은 서명자들의 무관심한 환경의 비디오를 녹화함으로써 KETI 수화 데이터 세트를 충분히 큰 규모로 확장하는 것도 중요하다



