오늘 정리한 내용은 스타일 트랜스퍼에 관한 내용입니다.
참고한 자료들은 하단의 [참고자료]에 기재하였습니다.
Transfer Learning

이러한 스타일 트랜스퍼를 이해하기 위해서는 전이학습이라는 개념이 우선되어야 해서 간단히 어떤 개념인지 살펴봐야한다. 우선 앞에서 살펴봤던 cnn구조를 recall해보면 위의 그림과 같은데, 이러한 cnn 구조를 이용해 학습시키는 과정을 다시 짚어보면, 다음과 같이 0에서 9까지의 숫자를 나타내는 흑백이미지인 MNIST 손글씨 데이터를 99%이상 인식하기 위해서는 보는 것과 같이 3개의 CONvolution층과 한 개의 완전연결층 즉 fully connected층이 필요했고 전체 학습에 소요되는 시간은 CPU 1개인 환경에서 약 1시간정도 걸리게 된다.
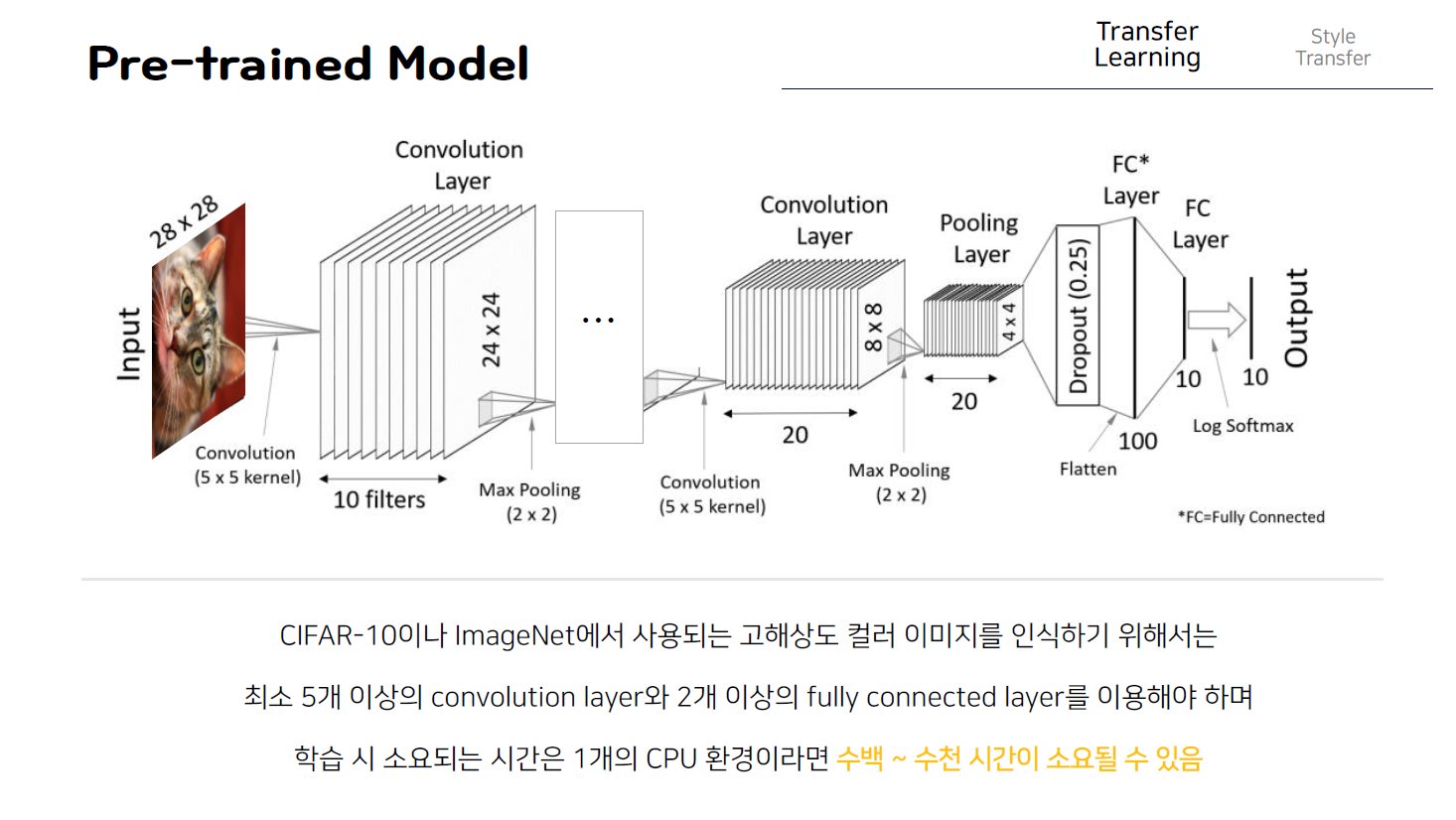
하지만 MNIST와 같은 흑백이미지가 아니라 다음과 같이 CIFAR10과 같은 고해상도의 칼라 이미지를 우리가 지금까지 학습했던 CNN 구조로 인식하기 위해서는 최소 5개 이상의 convolution층과 2개 이상의 완전연결 층을 이용해서 입력으로 주어지는 복잡한 이미지의 특징 즉 feature를 추출하는 학습과정을 거쳐야한다. 그리고 이때, 소요되는 시간은 동일한 cpu1개의 환경 기준 수백~ 수천시간이다.

즉, 학습데이터가 고해상도의 칼라이미지라면 이를 분석하고 학습하기 위해서 처음부터 CNN 구조를 설계하고 그에 해당하는 가중치와 Bias hyperparameter값을 임의의 값으로 초기화한 다음 학습하는 경우 굉장히 오랜 시간이 소요되는 치명적인 단점이 존재하게 된다. 하지만 이때 고해상도의 칼라이미지에 잘 훈련된 사전 학습된 pre trained된 cnn 모델이 있다면, 우리는 이러한 cnn 모델을 바탕으로 우리가 분석하고자 하는 이미지 데이터에 맞도록 이미 학습되있는 cnn 모델의 다양한 파라미터 등을 tuning해서 사용함으로써 임의의 값으로 초기화된 파라미터를 처음부터 학습시키는 것에 비해 소요시간을 획기적으로 줄일 수 있으며 다양한 이미지 데이터를 짧은 시간에 학습할 수 있다는 장점이 존재하게 된다.
따라서 실무에서는 고해상도 칼라이미지를 학습하는 경우 cnn 아키텍처를 구축하고 임의의 값으로 초기화된 파라미터 값 가중치, 바이어스 등을 처음부터 학습시키지 않고, 대신 고해상도 칼라 이미지에 이미 학습되어있는(pre-trained) 모델의 가중치와 바이어스를 자신의 데이터로 전달 즉 transfer하여 빠르게 학습하는 방법이 일반적이다. 이처럼 고해상도 컬러 이미지 특성을 파악하는데 있어 최고의 성능을 나타내는 마이크로 소프트의 resnet, 구글의 Inception 모델 등을 이용하여 우리가 원하는 데이터에 미세조정 즉 fine tuning으로 불리는 작은 변화만을 주어 학습시키는 방법을 transfer learning 즉 전이학습 이라고 하게 된다.
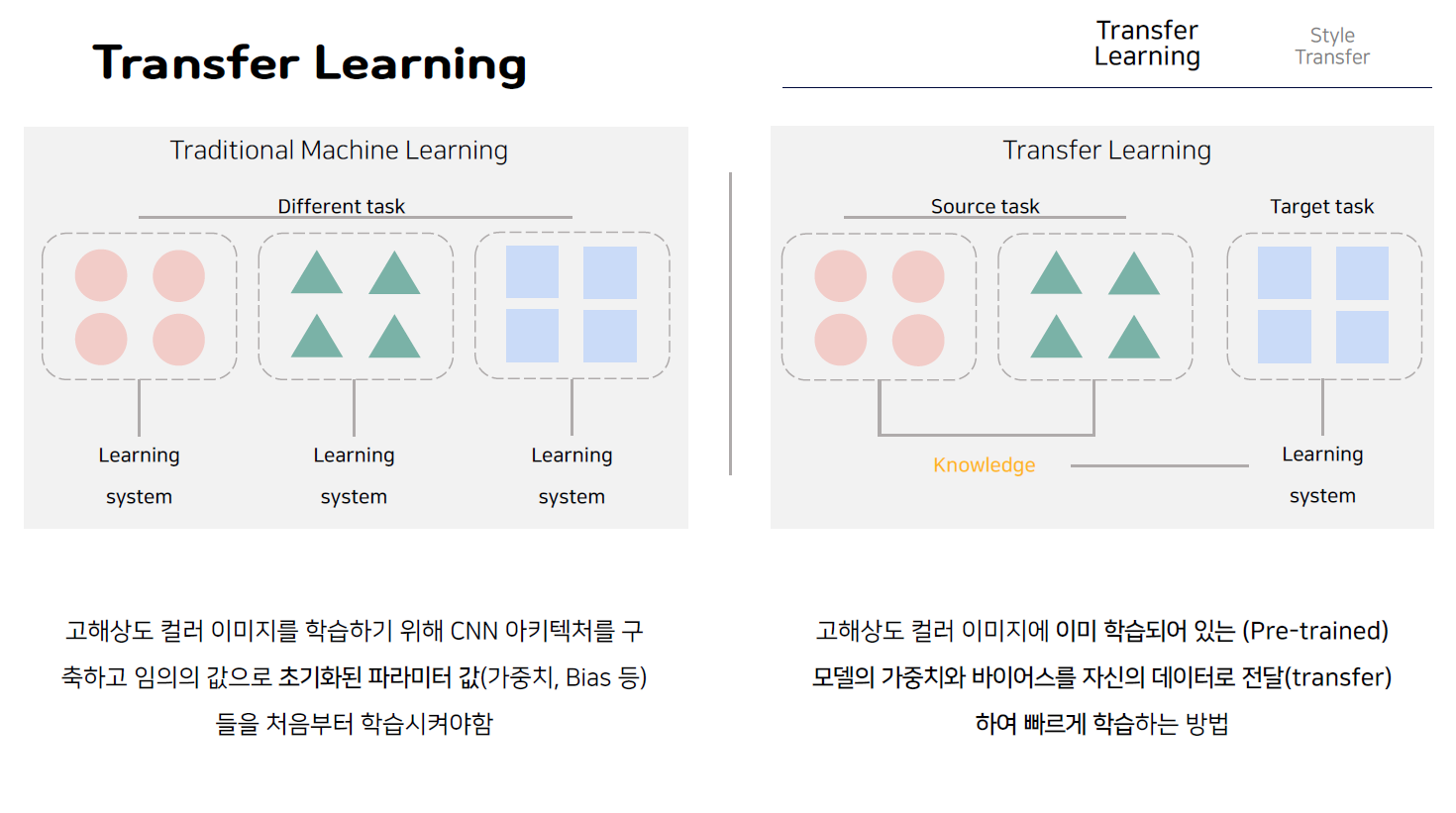
이러한 전이학습을 그림을 통해서 직관적으로 이해해보면, 먼저 일반적으로 우리가 아는 머신러닝의 학습과정은 다음과 같이 동그라미 데이터 세모 데이터 네모 데이터에 대해 각각 가중치와 바이어스 하이퍼파라미터 등의 값들을 독립적으로 학습시켜야 해서 많은 시간이 소요되는 반면, 방금 살펴본 전이 학습의 개념의 경우 다음과 같이 먼저 동그라미와 세모 데이터에 대해 학습이 잘 되어있는 pretrained 모델의 파라미터 값을 가져와서 우리가 새롭게 분석하고자 하는 네모 데이터의 특징을 뽑아내기 위해서 이전에 학습으로부터 가져온 값들을 일부 조정 즉 fine tuning함으로써 전체 시스템을 학습하는 것이 아닌 네모데이터에 특화된 파라미터 값들만 조정하게 되고, 즉 적은 시간으로 학습을 할 수 있게 된다.
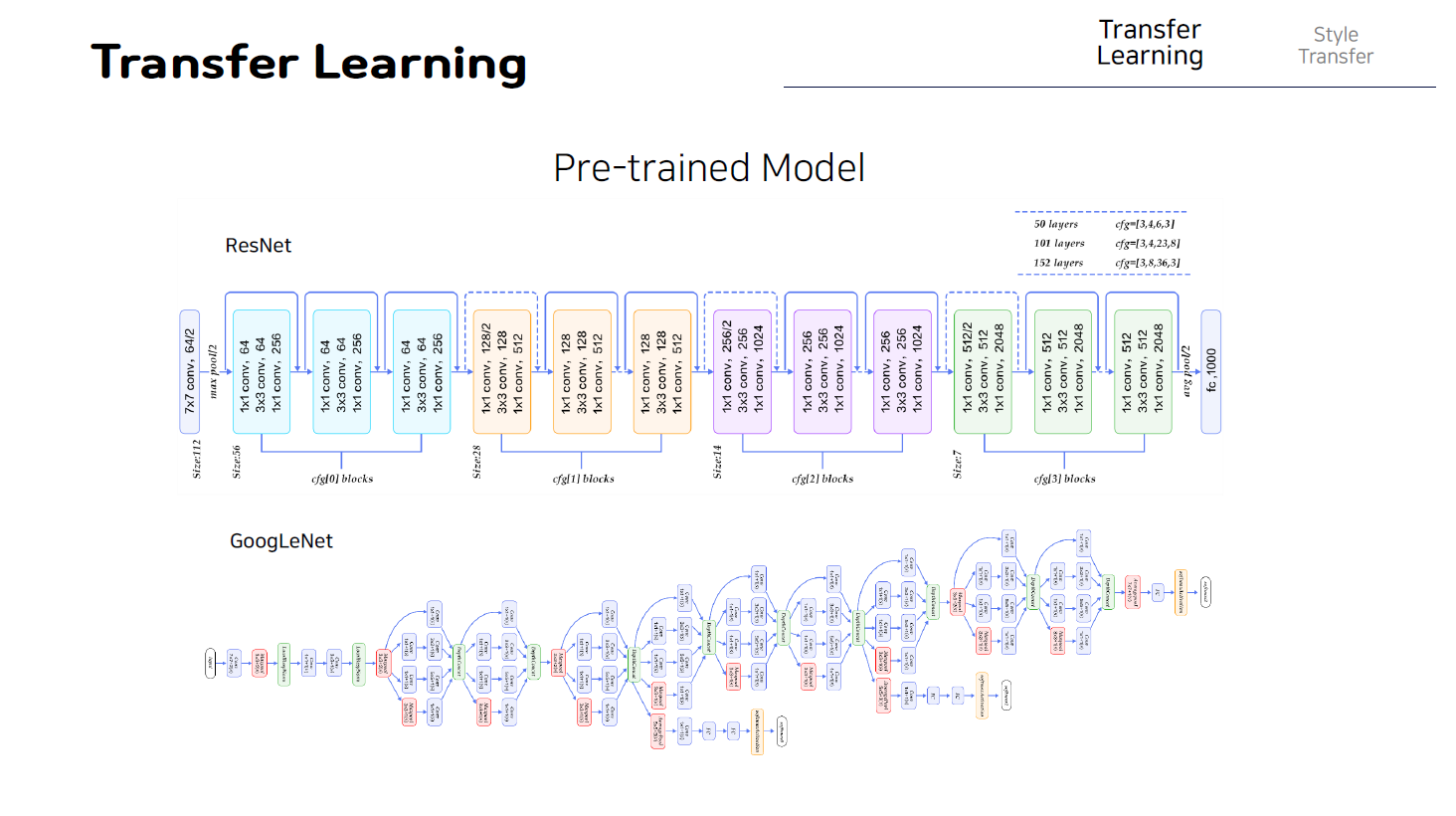
앞에서도 말했듯이 이러한 전이학습을 위해 사전학습되어 있는 모델은 많이 존재하지만 현재 내부구조와 소스가 공개되어있고 우수한 성능으로 다음과 같이 google의 inception 모델과 resnet모델이 가장 많이 사용되고 있다.

즉 예를 들어 다음 그림에서 이 왼쪽 부분은 합성곱 연산으로 이루어진 부분으로 어떤 특정 이미지넷과 같은 작업으로 미리 학습된 모델중에서 마지막 완전연결 네트워크 부분을 떼어낸 부분이고(그림은 정확하지 않습니다), 오른쪽 네트워크는 아직 학습이 안된 변수들로 이루어진 신경망이다. 이때 미리 학습된 왼쪽 부분을 어떤 이미지가 들어왔을 때 미리 학습된 필터들로 특성들을 추출한다 라고 해서 ‘특성추출기’라고 부르기도 한다. 만약 데이터가 부족한 상황이라면 이렇게 새롭게 붙인 오른쪽 네트워크의 변수에 대해서만 학습을 진행하고 왼쪽 특성 추출기의 변수는 고정해 놓는 것이다. 따라서 이와 같이 전이학습을 이용하면 데이터 부족을 어느정도 해결할 수 있다는 장점 또한 가지게 된다.
Style Transfer

그렇다면 이제 style transfer에 대해서 살펴보자. 책에서는 이 style transfer에 대한 개념이 굉장히 간단하게 나와있는데 개인적으로 잘 이해가 안가서 조금더 구체적으로 이해를 돕기위해 논문에 나온 개념들을 정리하였다.
Style transfer의 결과를 그림을 통해 보면 왼쪽 위에 이렇게 하나의 content 이미지가 있고 이러한 이미지의 스타일을 바꾼 결과이미지는 오른쪽 이미지와 같다. 보면 왼쪽 아래 이 작은 이미지가 스타일 정보를 담고 있는 이미지가 되고 왼쪽 이미지에서 집과 같은 물체가 있다는 정보, 즉 content 정보는 유지하고 스타일 정보들은 우리가 어떤 스타일이미지를 가져오냐에 따라 이렇게 바뀔 수 있게 되는 것이 바로 style transfer 방법인 것이다. 즉 우리는 한장의 이미지가 있을 때 그 이미지에 여러가지 스타일을 적용함으로써 임의로 풍경화와 같은 다양한 이미지를 생성할 수 있게 된다. 이러한 style transfer개념은 Image style transfer using convolution neural networks라는 cvpr 2016년도 논문에서 처음 발표가 되었으며 사실상 처음으로 딥러닝을 활용해 style transfer를 가능하도록 만드는 방법을 제안한 논문이다.

그렇다면 이 스타일트랜스퍼가 학습하는 가장 기본적인 원리를 먼저 살펴보자.
스타일 트랜스퍼는 방금 살펴본 것 처럼 최종 수행된 결과를 얻기 위해서 한장의 이미지를 업데이트하는 방식을 사용한다.
더욱 구체적으로 살펴보면 먼저 우리가 앞에서 살펴본 전이학습처럼 미리 사전 학습된 cnn 모델을 사용하며 이때 cnn 모델은 일반적으로 분류 모델을 사용한다. 원래 분류 모델이라는 것은 한장의 이미지가 들어왔을 때 그 이미지가 어떤 class인지를 알려주는 모델 유형을 말하는데 이제 그렇게 학습된 cnn 모델을 하나 가져와 사용하는데 이때 그 cnn 네트워크의 가중치는 고정시킨 뒤 이미지를 업데이트하는 방식을 사용하게 된다. 다시 말해서 일반적으로 우리가 학습이라고 한다면 어떤 네트워크의 가중치 값들을 업데이트 하는 것을 의미하는데 여기서 학습이란 한장의 이미지를 업데이트 하는 것으로 이해하면 되는 것이다.
즉 하나의 이미지를 준비하고 이어서 하나의 손실함수를 정의한 다음 그 손실 값이 작아지는 방향으로 이미지를 업데이트 함으로써 이미지를 optimization할 수 있게 된다. 그래서 일반적으로 content이미지와 같은 크기의 한장의 이미지를 준비하고 맨처음에는 이렇게 이미지의 값을 임의의 노이즈 값으로 초기화하고 그 뒤에 이러한 이미지 x를 조금씩 업데이트해서 우리가 원하는 결과가 나올 수 있게 만드는 것이다. 예를 들어서 단순하게 노이즈 이미지 x가 이 target이미지인 고양이 이미지와 같은 형태가 될 수 있도록 업데이트를 한다면 이렇게 이미지를 업데이트 하면 할수록 고양이 이미지와 유사해지는 것을 확인할 수 있다. 이런식으로 우리는 한장의 이미지를 준비하고 그 이미지를 조금씩 업데이트 하면서 스타일 트랜스퍼를 수행한 결과를 만들어낼 수 있도록 할 것이다.
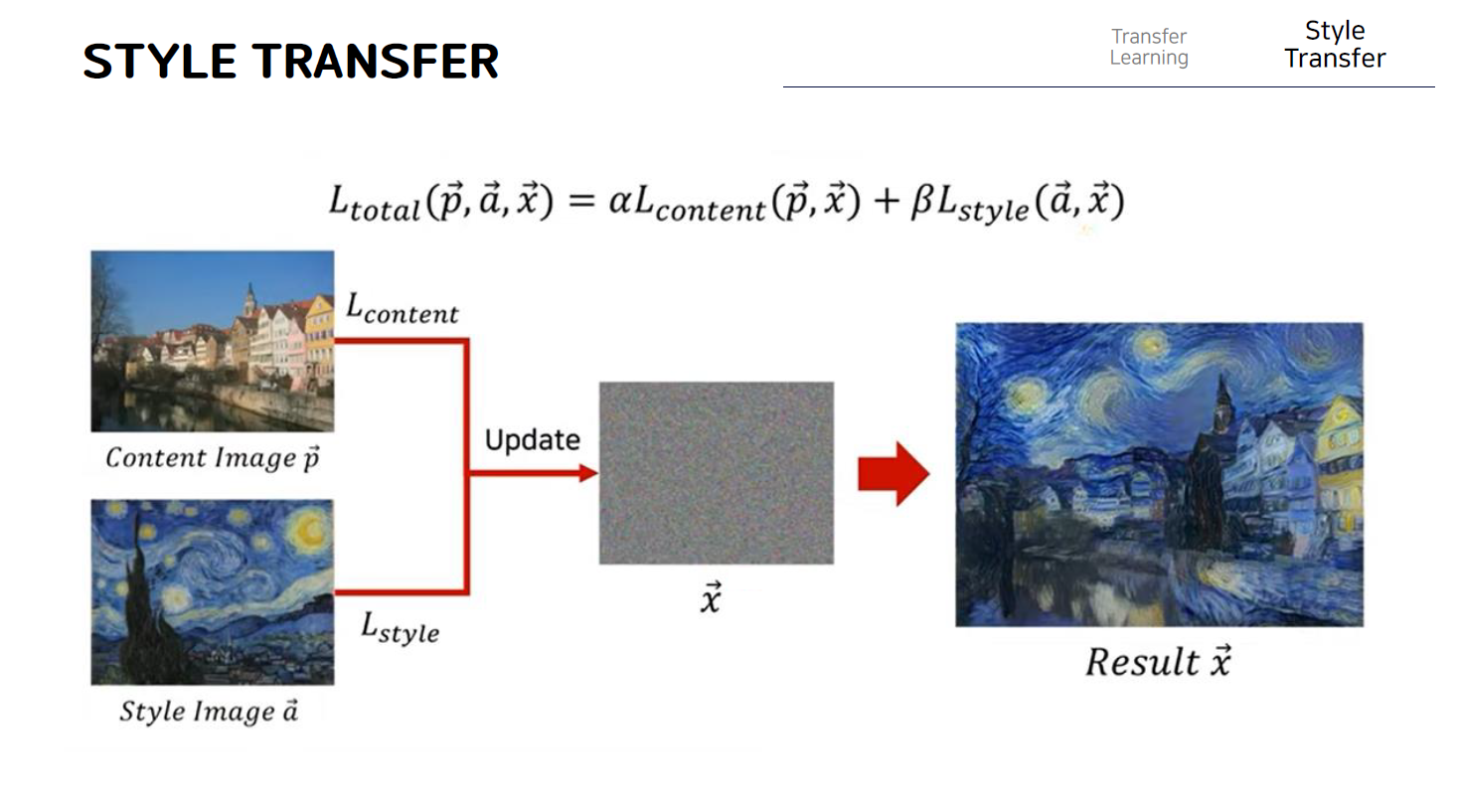
결과적으로 이미지 스타일 트랜스퍼를 조금 더 수식적으로 표현하기 위해서 논문의 수식을 살펴보면, 다음과 같다. 여기서 각각의 이미지를 이렇게 벡터로 표현한 이유는 사실 한장의 이미지는 이런식으로 세로축과 가로축으로 구성된 한장의 행렬과 같은 데이터라고 볼 수 있지만 이런 이미지 또한 그냥 왼쪽위부터 쭉 일렬로 나열하는 방식으로 하나의 벡터로써 표현할 수 있기 때문에 하나의 이미지를 표현할 때 벡터 형태의 변수로써 표현하게 된다. 따라서 이 왼쪽 위의 content image를 p라고 하고 style image를 a라고 부른다고 가정하고 우리는 앞에서 말했듯이 하나의 노이즈 이미지인 x를 update하는 방식으로 style transfer를 수행하는 결과를 얻을 수 있게 된다. 여기에서 우리는 content image로부터 content 정보를 가져오고 style 정보는 style이미지로부터 가져온다.
따라서 이를 위해 Lcontent 와 Lstyle 이렇게 두가지 loss를 정의해주게 되고 content loss의 값이 줄어든다는 것은 content 정보를 잘 받아왔다는 것이고 style loss값이 줄어든다는 것은 이런 style image로부터 style 정보를 잘 받아왔다는 의미가 되는 것이다. 결과적으로 이러한 이미지 x를 업데이트할 때 content loss와 style loss를 둘다 줄이는 방식을 사용함으로써 우리는 결과적으로 이미지 x를 업데이트할 때 이렇게 더하기를 사용해서 두가지 loss를 같이 줄이는 방식으로 업데이트를 하게 되면 만들어지는 이미지 x는 style transfer가 수행된 결과와 같다는 것을 확인할 수 있다.
그렇다면 이제 이러한 손실함수를 어떻게 정의할 수 있는지 간단히 살펴보도록 하자.
이를 위해서는 cnn에서의 특징맵 즉 feature map에 대한 이해가 필요하다. 일반적으로 어떠한 이미지를 분류하기 위한 목적의 cnn은 layer가 깊어질수록 채널의 수가 많아지고 너비와 높이는 줄어든다. 이때 컨볼루션 레이어의 서로 다른 필터들이 각각 적절한 특징 즉, feature를 추출하도록 학습되는데, 즉 예를 들어 6개의 필터가 있을 때 첫번째 필터는 입력으로 주어진 정보에서 뾰족한 object를 검출하는 방식으로, 두번째 필터는 다양한 동그라미와 같은 무늬정보를 검출하는 방식으로 동작할 수가 있는 것이다. 그래서 각각의 필터마다 output data에서의 각 channel에 대한 결과를 만드는 것과 유사하다고 볼 수 있다. 다시말해서 하나의 feature map 혹은 activation map이 있을 때 각각의 채널들은 서로 다른 feature들을 추출한 결과라고 할 수 있다. 이러한 cnn의 기본 동작을 적용해서 이제 content loss와 style loss를 정의해보자.
Content Loss
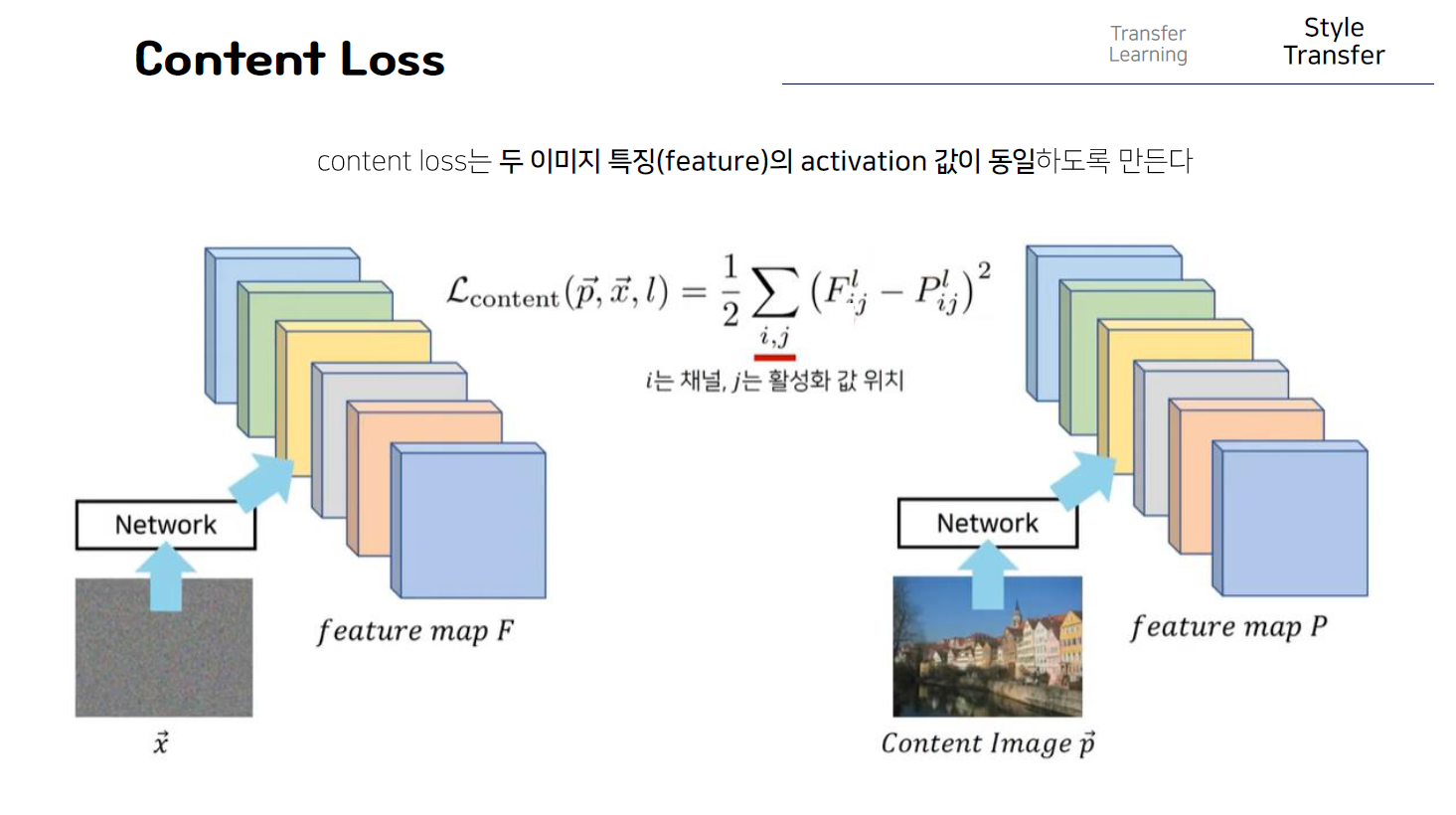
우선 content loss이다. 이 content loss는 단순히 두 이미지의 특징 값 자체가 같아질 수 있도록 즉 activation 값이 동일하도록 동작한다. Cnn은 여러 개의 layer로 구성되어있는데 이때 어떤 이미지 x가 있을 때 그 이미지를 특정 cnn 모델에 넣었을 때 특정 layer에서의 결과값 즉 하나의 feature 맵이 있다고 했을 때 그것을 F라고 하고 마찬가지로 이미지 p로부터 얻은 feature map을 p라고 가정을 해보자. 이때 두개의 network는 실제로는 같은 network를 사용한 것이고 이렇게 feature map P를 뽑을 때도 마찬가지로 같은 LAYER에서 나오게 된 OUTPUT을 비교하는 것이다.
따라서 이러한 수식에서 F와 P는 각각 feature map이 되는 것이고 이때 l은 정확히 몇번째 layer를 사용할 것인지를 명시하고 i는 channel, j값은 해당 channel의 실제 feature 값의 위치를 의미하는 것이다. 예를 들어 특정 layer l에서 뽑은 feature map이 이렇게 생겼다고 한다면 이 feature map에서 각각의 채널들은 이 피처들 하나하나를 의미하는 것이고 여기서는 channel의 개수가 6이 된다. 이때 각각의 채널들마다 이 j를 이용해 각각의 위치값을 표현할 수 있는 것이다. 다시말해 content loss는 content image p 와 우리가 업데이트하고 있는 노이즈 이미지인 x간에 content를 유사하게 만들기위해서 각각의 이미지를 cnn에 넣어서 나온 feature map에서의 값 자체가 유사하게 만들어주는 것이다. 즉 간단히 말해 여기서 feature map F와 feature map P에서의 동일한 위치마다 서로 1:1로 비교를해서 각각의 위치마다 값자체가 동일해질 수 있도록 UPDATE해주는 것이다!
Style Loss
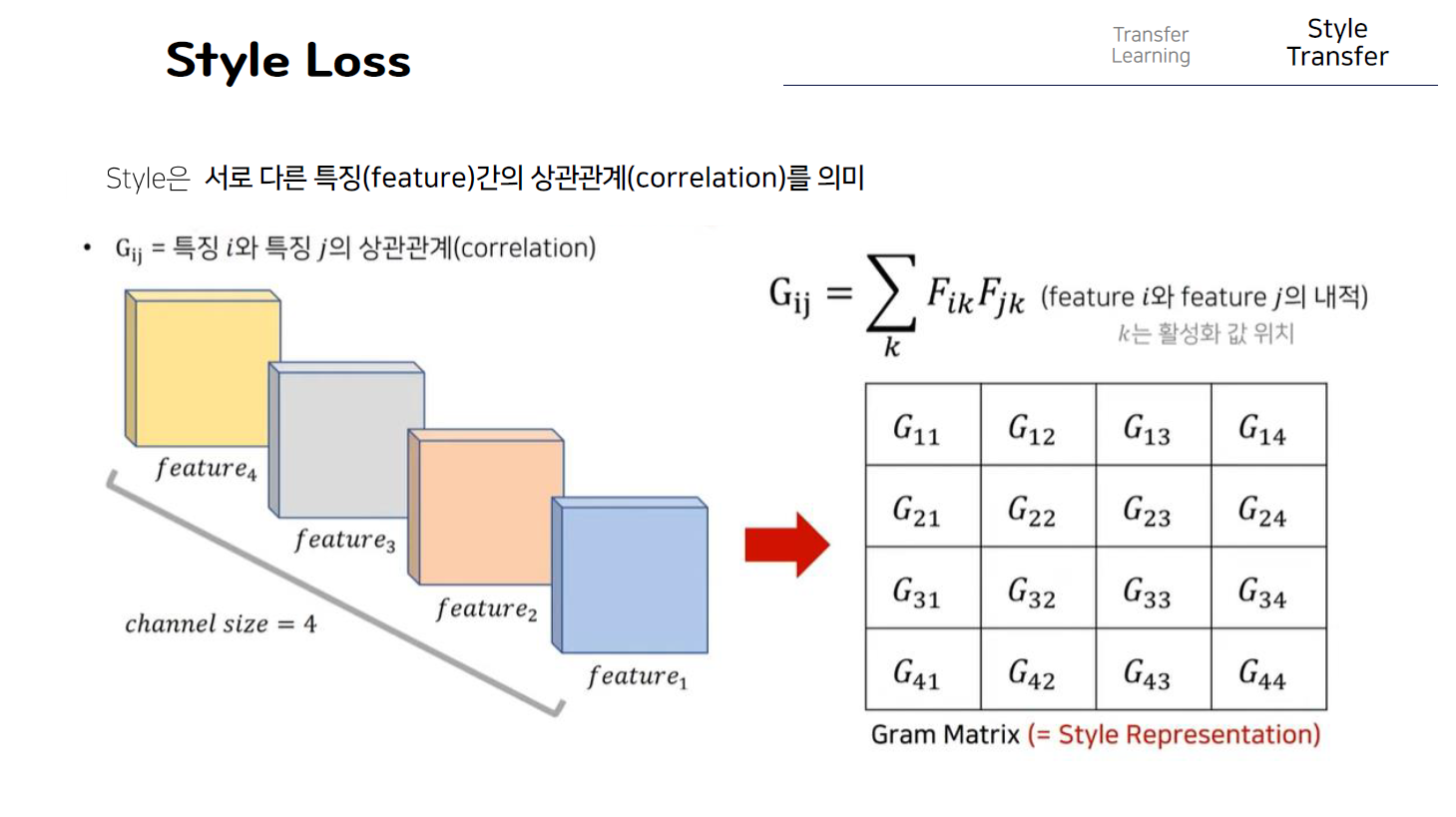
다음으로 style loss에 대해서 살펴보자. 본 논문에서는 Style은 서로 다른 특징간의 상관관계로 정의한다. 즉 말그대로 여러 개의 feature들이 있을 때 그러한 feature간의 상관관계 그 자체를 style로 정의를 하는 것이고 만약 두개의 이미지가 있을 때 그 두개의 style이 같다는 것은 두 이미지 각각에 있는 그 특징들의 상관관계 정도가 유사하다고 볼 수 있게 된다. 이를 수학적으로 표현해보면 다음과 수식과 같은데 우선 마찬가지로 특정 layer에서 나온 출력 feature map이 이렇게 있다고 해보면 보면 channel size가 4인 것을 확인할 수가 있고 이는 즉 cnn layer에서 사용했던 filter의 개수가 4개라는 것을 의미하고 즉 서로 다른 특징들이 이렇게 총 4개가 존재한다고 볼 수 있다. 이때 Gij는 특징 i와 특징 j의 상관관계라고 정의를 했을 때 우리는 이것을 이러한 수식으로 표현할 수 있게 된다. 여기서 상관관계라는 것은 두개의 feature가 있다고 했을 때 하나의 feature에서 높은 activation값이 나왔다고 하면 다른 하나의 feature에서도 높은 activation값이 나오는 것을 의미한다. 예를 들어 feature1과 feature 2의 상관관계가 높다는 것은 feature 1에서 높은 activation이 나오는 경우 feature 2에서도 높은 activation이 나온다는 것이다. 이를 표현하기 위해 이러한 matrix를 사용하고 각각의 원소들은 서로 다른 채널 즉 서로 다른 두개의 특징간의 상관관계를 표현한 것이라고 할 수 있다. 이 matrix의 각각의 원소 값은 이러한 수식대로 계산하게 되는데, 이때 i랑 j는 서로 다른 feature값 즉 서로다른 channel을 의미하고 그러한 feature에 존재하는 각각의 원소들이 k로 표현이 되게 된다. 즉 각각의 위치에 대해서 그 값을 서로 곱한 것을 모두 더할수 있도록 하는 것이다. 이 값이 크다는 것은 두 feature간의 상관관계가 높다고 볼 수 있게 된다. 그래서 결과적으로 우리는 하나의 이미지를 네트워크에 넣어 특정 layer에서 나온 이러한 feature맵에 대해서 Gram matrix를 구해서 각각의 feature들이 서로가 서로에게 얼마나 많은 상관관계를 가지고 있는지를 수치화 할 수 있게 되는 것이다. 이렇게 만들어진 gram matrix는 당연히 feature의 개수가 높이와 너비와 같다는 것을 알 수 있다.
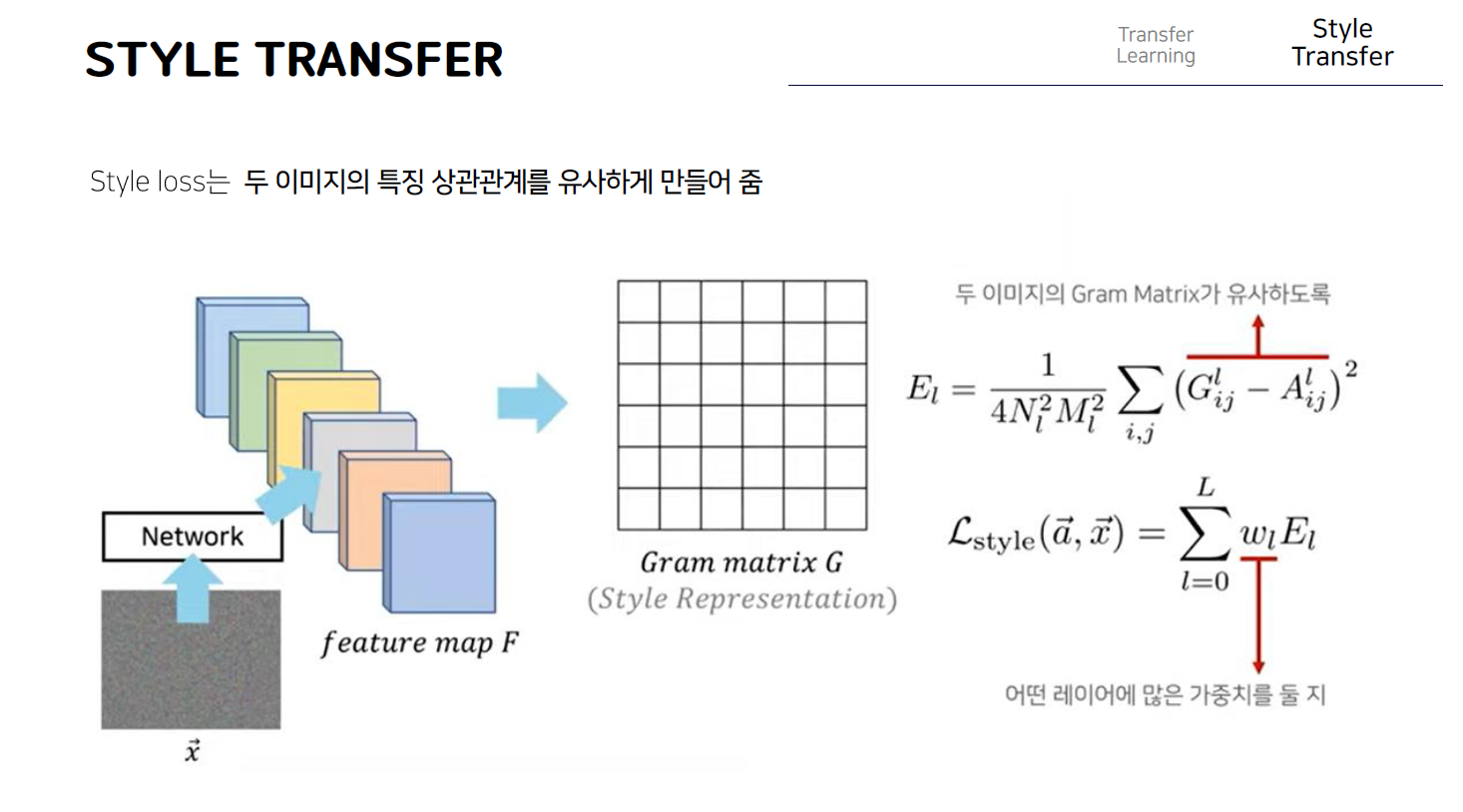
즉 최종적으로 이러한 gram matrix의 값 자체를 그 이미지의 style이라고 볼 수 있다!
따라서 style loss라는 것은 이러한 gram matrix를 사용하는 것이고 두 이미지의 gram matrix의 값이 같도록 만들어서 두 이미지의 style값이 유사할 수 있도록 만드는 방식으로 동작한다. 즉 이러한 스타일 손실값을 줄이는 방향으로 업데이트 함으로써 style image로부터 style 정보를 가져올 수 있게 된다. 이떄 style loss같은 경우는 여러 개의 layer를 사용하는 경우가 많은데 앞에서 살펴본 content loss같은 경우는 일반적으로 하나의 layer에 대해서 그 feature 맵 자체가 같아질 수 있는 형태로 업데이트를 하지만 style loss같은 경우에는 3개에서 4개 정도의 layer를 정한 다음 그 layer에서의
값들에 대해 각각 다 Gram matrix를 구한 다음 각각의 layer에 대해 모두 gram matrix가 유사해질 수 있도록하는 것이다. 따라서 여기서 E l은 특정 layer l 에대한 GRAM matrix의 차이값이라고 할 수 있고 참고로 특정한 값으로 나누어준 과정은 그 값이 너무 클 수 있기 때문에 normalization term을 넣어준 것이다.
최종적으로 style loss를 구할 때 어떤 layer를 사용할지 미리 결정해놓은 그 값에 따라서 각각의 layer에 대해서 전부다 El 값을 구한뒤에 전부다 손실값을 줄일 수 있는 형태로 update를 진행한다고 볼 수 있다. W l의 경우는 어떤 레이어에 더 많은 가중치를 둘지 설정하기 위해서 넣어주는 hyperparameter다.
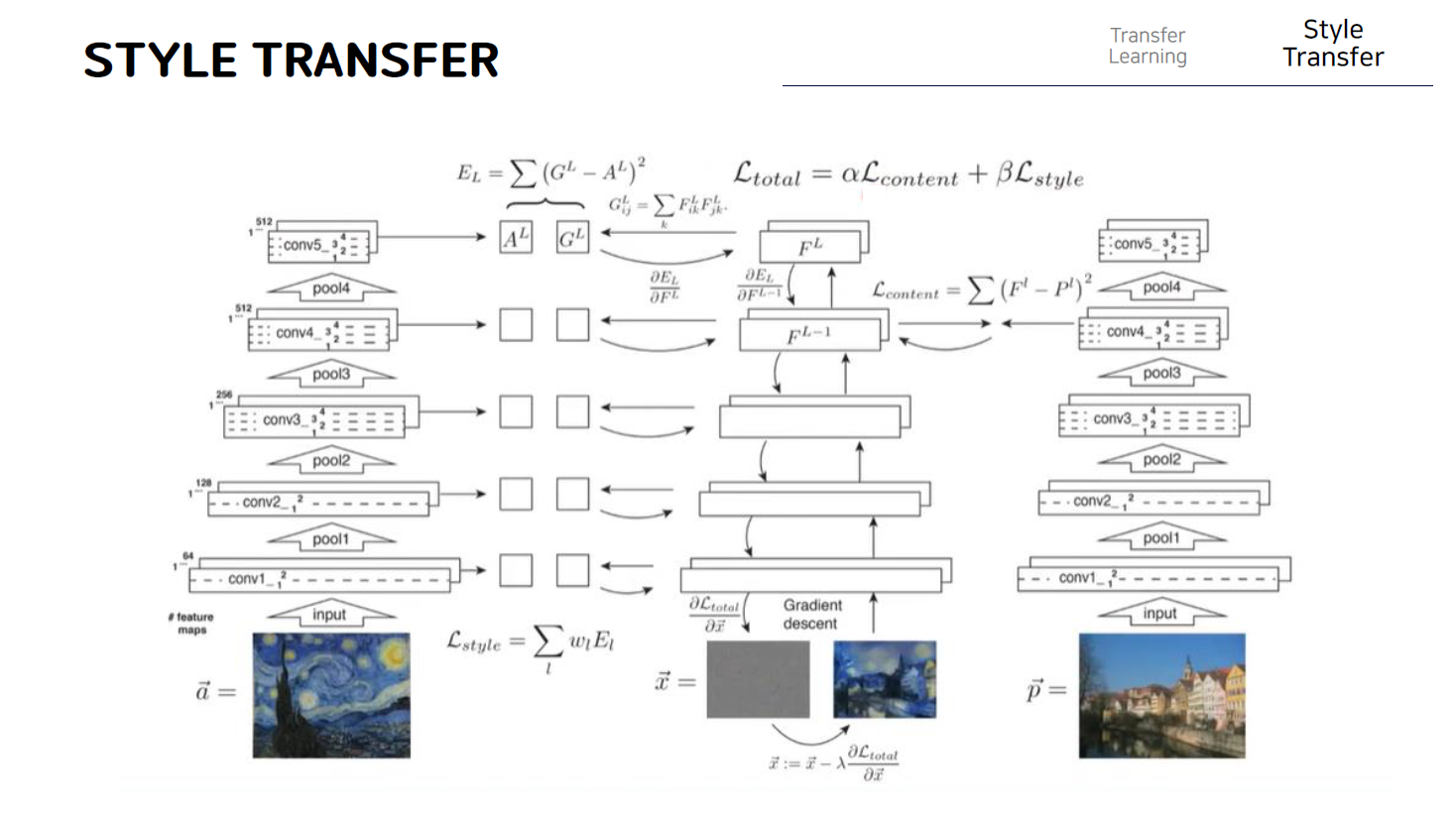
결과적으로 style transfer 알고리즘을 한장의 그림으로 요약하면 다음과 같다. 왼쪽에는 style image가 있고 오른쪽에는 content이미지가 있다. 우리는 노이즈 이미지인 x를 조금씩 업데이트해서 a로 부터는 style을 p로 부터는 content를 가져오게 된다. 그래서 결과적으로 이 최종 loss function에 의해서 update가 이루어지게 되고 이 content와 style에 대해 각각 얼마만큼 가져올지에 대해 가중치를 부여하기 위해 알파와 베타 파라미터를 넣어주게 된다. 결과적으로 이러한 loss를 이미지인 x로 미분해서 얻은 gradient값으로 조금씩 업데이트를 반복해서 결과이미지를 만들어낼 수 있다. Content loss는 한장의 content 이미지를 vgg 네트워크에 넣어 conv4 layer에서 나온 output feature값과 우리가 업데이트하고 있는 이미지 x의 output feature값을 비교해서 그 값들이 서로 일치하는 방향으로 loss값을 설정한 것을 확인할 수 있고,
반면에 style loss의 경우에는 하나의 layer가아니라 여기서는 총 5개의 layer를 사용해서 각 feature map에 대해서 먼저 gram matrix를 구하고 이러한 gram matrix가 일치할 수 있는 방향으로 업데이트 할 수 있도록 한다.
따라서 이미지 x는 style loss와 content loss를 모두 줄일 수 있는 방향으로 update가 되기 때문에 이미지를 여러 차례 업데이트하게 되면 오른쪽그림과 같은 결과이미지를 얻을 수 있게 된다
Pytorch code

이제 style transfer를 pytorch 코드로 구현하는 부분을 살펴보자.
우선 style transfer모델은 계속해서 살펴봤듯이 전이학습을 이용하기 때문에 우선 사전 학습된 resnet 50 모델을 불러온다. 그리고 이 모델을 그대로 사용하는 것이 아닌 우리는 content loss와 style loss를 계산해야하기 때문에 모델의 layer 중 feature map을 뽑아내고 싶은 위치를 설정해주고 이때 네트워크 변수들은 학습 대상이 아니기 때문에 기울기 계산은 멈춰준다.

다음은 이제 style loss를 계산하기 위해 필요한 Gram matrix를 생성해준다. Torch.bmm이라는 함수는 tensor에서 배치 크기 부분은 연산에서 제외하고 행렬곱 연산을 수행하는 함수다.
이렇게 네트워크 그리고 손실함수가 준비되었으니 style image와 content image 그리고 생성할 이미지를 설정해준다. 이떄 style 과 content image는 학습 대상이 아니기 때문에 requires_grad를 False로 설정해준다. 그다음 학습 동안 변함 없는 스타일 목푯값과 콘탠트 목푯값을 지정해주고, 이때 style loss는 서로 다른 크기의 gram matrix에서 발생하는데 그 값을 정규화 해주기 위해 각 위치에서 발생한 손실을 그람 매트릭스의 가로세로 크기로 나누어 총 style loss를 계산한다.

최종적으로 L-BFGS 최적화 함수를 설정한다. 이 함수는 기존 기울기들을 기억해 2차 미분값을 계산하기 때문에 클로저를 작성해 1차 미분값들을 전달해주고 함수 내부는 1차 미분으로 학습할 때와 똑같이 구성되어있게 된다.
(코드는 참고용으로 완벽한 코드가 아님)
[참고자료]
나동빈님의 유튜브 : https://youtu.be/va3e2c4uKJk
NeoWizard님의 유튜브 : https://youtu.be/ubKWak6MGm0



